Enroll to explore sandbox
Kindly fill up the following to try out our sandbox experience. We will get back to you at the earliest.
Kindly fill up the following to try out our sandbox experience. We will get back to you at the earliest.
Discover what Data Vault is, its components, origins, and benefits for data management.
Updated on

Organizations struggle to keep pace with the overwhelming volume and complexity of data. Data Vault emerges as a powerful methodology designed to simplify this challenge, providing a structured approach through its core components: Hubs, Links, and Satellites. This framework enhances data management while ensuring compliance and adaptability in dynamic environments. Exploring the origins, components, and benefits of Data Vault reveals its transformative potential for businesses striving to navigate the complexities of modern data governance.
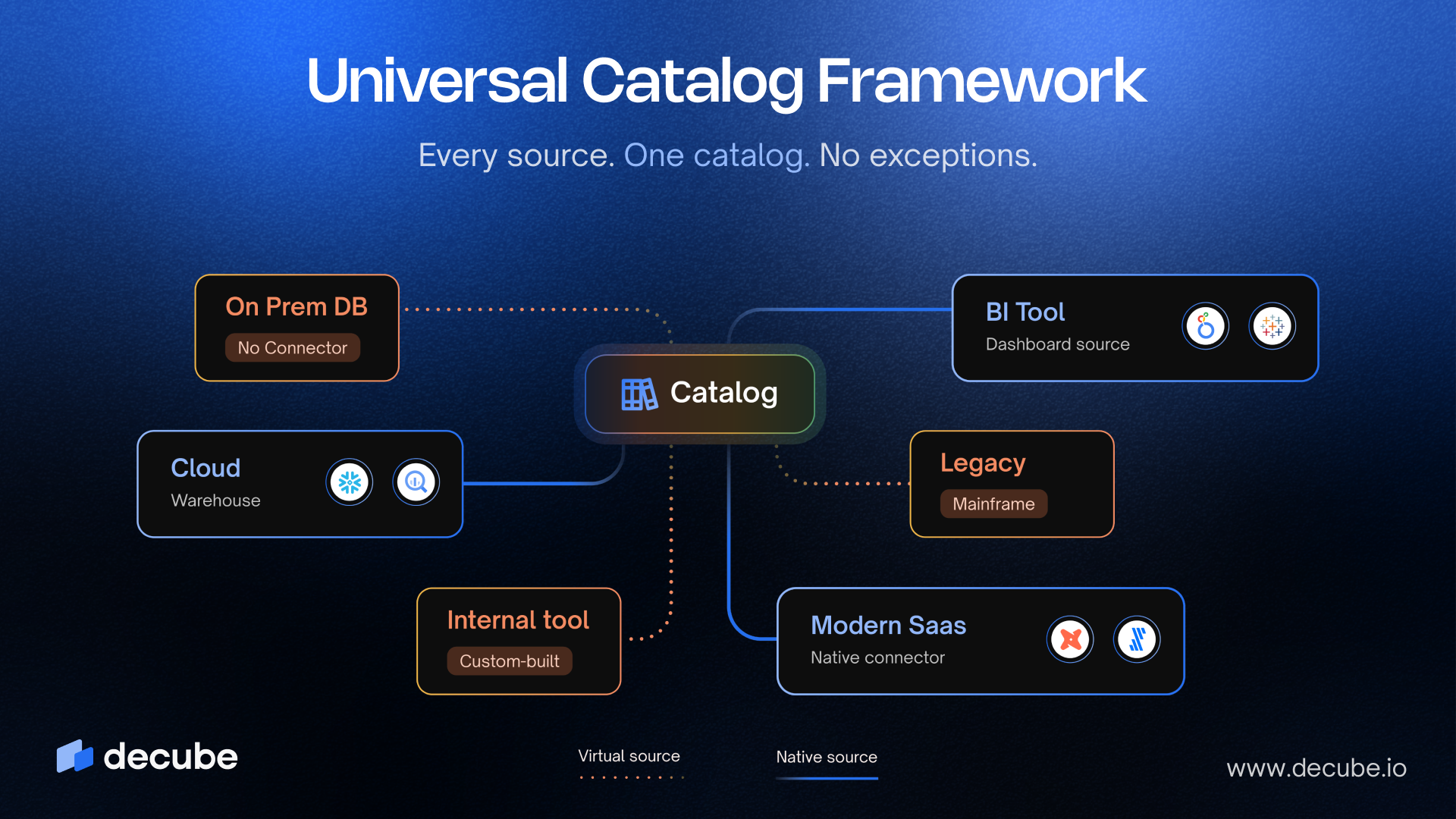
In an era where data management is paramount, Vault offers a robust methodology that addresses the complexities of warehousing. It is structured around three core components: Hubs, Links, and Satellites. Hubs serve as repositories for unique business keys, such as Customer IDs or Product IDs, ensuring that each key is distinct and easily traceable. Links establish relationships between these Hubs, capturing interactions, such as a customer's purchase of a product. Satellites, conversely, store descriptive attributes and monitor historical changes, offering context and depth to the information.
This architecture allows organizations to bring in information from different sources while keeping a clear audit trail, which is crucial for compliance and regulations. The immutability of the Raw Information Layer ensures that historical records remain intact, supporting strict lineage and auditability-essential features for industries like finance and healthcare.
As of 2026, a significant percentage of organizations have adopted Vault for their management needs, recognizing its ability to support scalability and resilience even as volumes increase. Businesses often struggle with adapting to rapid changes in information environments, which can disrupt operations. The methodology's focus on distinguishing raw information from business rules enables swift adjustments with minimal interruption, making it an ideal option for businesses maneuvering through these challenges.
The platform enhances this process with its comprehensive lineage visualization, allowing engineers to oversee information flows effortlessly and uphold trust across their operations. Users have praised the software for its user-friendly interface and effective management of information quality, facilitating early issue detection. Moreover, Decube's automated crawling feature streamlines metadata management and secure access control, ensuring that information quality is maintained throughout the information lifecycle. By adopting this framework, organizations can significantly improve their decision-making processes and operational efficiency.

The information repository methodology, developed by Dan Linstedt in the 1990s, addresses the limitations of traditional warehousing. It was specifically designed to tackle the challenges of integrating diverse information sources while ensuring historical accuracy and auditability. Since its inception, the storage framework has undergone considerable development, particularly with the launch of version 2.0 in the early 2010s. This revised edition incorporates best practices tailored for large information sets and NoSQL environments, enhancing its relevance in today’s complex informational ecosystems.
A recent survey revealed that 62% of organizations plan to enhance their information storage utilization, with 34% of top-performing companies currently employing it. As organizations strive for modernization, the significance of this methodology becomes increasingly apparent, highlighting its role in improving information practices and quality. The evolution of information storage systems reflects a broader shift towards more adaptable and scalable management solutions, establishing it as an essential element in the toolkit of professionals navigating the complexities of modern information environments.
In this context, the platform exemplifies what is data vault and demonstrates how modern tools can enhance its principles. The platform has received positive feedback for its automated column-level lineage, which significantly enhances data observability, enabling business users to swiftly identify issues in reports and dashboards. The platform's automated crawling feature ensures that metadata is effortlessly managed, eliminating the need for manual updates once information sources are linked. Furthermore, the platform's intuitive design fosters trust in information, facilitating easy monitoring of quality and encouraging collaboration among teams. This feedback emphasizes Decube's role in improving information governance and quality, aligning seamlessly with the advancing information storage methodology.

Data Vault architecture is fundamentally structured around three key components: Hubs, Links, and Satellites, each serving a distinct purpose in data management. Hubs act as the foundational elements, storing unique business keys that represent core business entities, such as customers or products. Each Hub is designed to maintain stability and integrity, ensuring that the identifiers used are durable and reliable.
Links play a crucial role in establishing relationships between Hubs, capturing events or transactions that connect different entities. For instance, a Link might represent a customer placing an order, effectively linking the customer Hub to the product Hub. This relational aspect is vital for understanding the interactions within the information ecosystem.
Satellites play a crucial role by complementing Hubs and Links, as they store descriptive attributes and track historical changes. Whenever a modification takes place in the source systems, a new version is documented in the corresponding Satellite, ensuring that organizations maintain a comprehensive perspective of their information over time. Thus, this capability is vital for ensuring compliance and supporting effective auditing processes.
The platform enhances this architecture with its automated crawling feature, eliminating the need for manual metadata updates, which can lead to a 30% reduction in data management time. Once sources are linked, metadata is auto-refreshed, ensuring that information remains current and relevant. Furthermore, this platform offers comprehensive lineage visualization, illustrating the entire journey of information as it moves across various systems-from source to transformation to consumption. Consequently, this feature fosters trust and reliability in data management practices. Moreover, Decube enables organizations to manage who can see or modify information via a specified approval process, improving information governance and security.
Understanding what is data vault reveals how its modular nature enhances flexibility and scalability, allowing organizations to adapt quickly to evolving business requirements. Optimal approaches for executing these elements involve ensuring that Hubs are clearly defined and stable, utilizing Links to accurately depict relationships without complicating the model, and leveraging Satellites to capture all pertinent changes while minimizing duplication. This organized method not only supports efficient information management but also facilitates the integration of new sources and analytical tools, further enhanced by Decube's automated monitoring and analytics capabilities.

The Data Vault approach addresses significant challenges in data governance and compliance faced by organizations today. Compartmentalizing information into distinct components allows organizations to monitor changes effectively and maintain a comprehensive history of transformations, addressing significant challenges in data governance. This organized method is crucial for meeting regulatory compliance requirements like GDPR and HIPAA, as it enables enhanced information lineage and traceability.
Organizations employing a structured approach have reported higher compliance rates, as the methodology facilitates systematic documentation and monitoring of information flows, which is essential for regulatory adherence. Moreover, the inherent flexibility of the framework makes it well-suited for environments characterized by rapidly changing information requirements, allowing organizations to quickly respond to new business needs without incurring extensive rework.
This agility is especially advantageous in fields such as healthcare, where adherence to strict regulations is essential and the expense of breaches can average over $7 million. By implementing a Vault, organizations not only enhance their management capabilities but also strengthen their compliance frameworks, ensuring they remain robust in the face of regulatory challenges.
Furthermore, the automated crawling capability enhances information observability by guaranteeing that metadata is automatically updated once sources are linked, thus minimizing manual updating efforts. The end-to-end lineage visualization from the company allows organizations to trace information flows, identify root causes, and evaluate downstream effects efficiently.
Ultimately, organizations that understand what is data vault methodology position themselves to navigate regulatory landscapes with confidence and efficiency.

The Data Vault methodology provides a structured framework for data management that enhances scalability and compliance. By focusing on its core components - Hubs, Links, and Satellites - organizations can effectively manage complex data environments while ensuring a clear audit trail and historical accuracy. This architecture facilitates the integration of diverse information sources and empowers businesses to adapt swiftly to changing data landscapes.
Throughout the exploration of Data Vault, key insights reveal its historical evolution, from its inception in the 1990s to its current relevance in modern data practices. The methodology's design addresses the challenges posed by traditional warehousing, enabling organizations to maintain comprehensive data lineage and governance. Moreover, the automated features offered by platforms like Decube further streamline metadata management and enhance data quality, making it easier for teams to collaborate and monitor their information assets.
In a world where data is a critical asset, implementing the Data Vault methodology is essential for organizations aiming to enhance their data management practices and ensure compliance. As businesses strive for modernization and efficiency, adopting this robust framework not only strengthens compliance but also fosters a culture of trust and reliability in data management.
What is the Data Vault methodology?
The Data Vault methodology is a robust approach to data management and warehousing that focuses on three core components: Hubs, Links, and Satellites.
What are Hubs in the Data Vault framework?
Hubs serve as repositories for unique business keys, such as Customer IDs or Product IDs, ensuring that each key is distinct and easily traceable.
How do Links function in Data Vault?
Links establish relationships between Hubs, capturing interactions, such as a customer's purchase of a product.
What role do Satellites play in the Data Vault architecture?
Satellites store descriptive attributes and monitor historical changes, providing context and depth to the information.
Why is the audit trail important in Data Vault?
The audit trail is crucial for compliance and regulations, allowing organizations to maintain a clear record of information from different sources.
What is the significance of the Raw Information Layer in Data Vault?
The Raw Information Layer ensures the immutability of historical records, supporting strict lineage and auditability, which is essential for industries like finance and healthcare.
How has the adoption of Data Vault changed by 2026?
A significant percentage of organizations have adopted Data Vault for their management needs, recognizing its ability to support scalability and resilience as data volumes increase.
What challenges do businesses face that Data Vault helps address?
Businesses often struggle with adapting to rapid changes in information environments, which can disrupt operations. Data Vault enables swift adjustments with minimal interruption.
How does Data Vault enhance information flow oversight?
The platform provides comprehensive lineage visualization, allowing engineers to oversee information flows effortlessly and uphold trust across operations.
What features do users appreciate about the Data Vault software?
Users praise the software for its user-friendly interface, effective management of information quality, early issue detection, automated crawling for metadata management, and secure access control.
How does adopting the Data Vault framework benefit organizations?
By adopting this framework, organizations can significantly improve their decision-making processes and operational efficiency.

First step to AI Readiness
Table of Contents
Sneak peek from the data world.











_For%20light%20backgrounds.svg)