Enroll to explore sandbox
Kindly fill up the following to try out our sandbox experience. We will get back to you at the earliest.
Kindly fill up the following to try out our sandbox experience. We will get back to you at the earliest.
Understand where your data comes from, how it transforms, and why that knowledge is now non-negotiable for governance, compliance, and AI.
Updated on
Data lineage is the end-to-end record of where a piece of data came from, every transformation it went through, and every downstream asset that depends on it. It maps the complete journey of data across your organization: from source systems through transformation layers to dashboards, reports, and AI model inputs.
Without lineage, answering any basic data question means interrogating engineers, reading SQL at 2am, or staring at a broken dashboard the night before a board meeting. With lineage, the answer is a click away.
Data lineage is not new. Enterprises have tracked data flows in some form for decades. What changed dramatically after 2024 is why it matters. The column-level data lineage market reached approximately $873 million in 2025, growing at over 15% CAGR. The primary driver is AI readiness: organizations deploying AI and ML workflows need to prove that every model input is accurate, traceable, and compliant. Lineage is the mechanism that makes that possible.
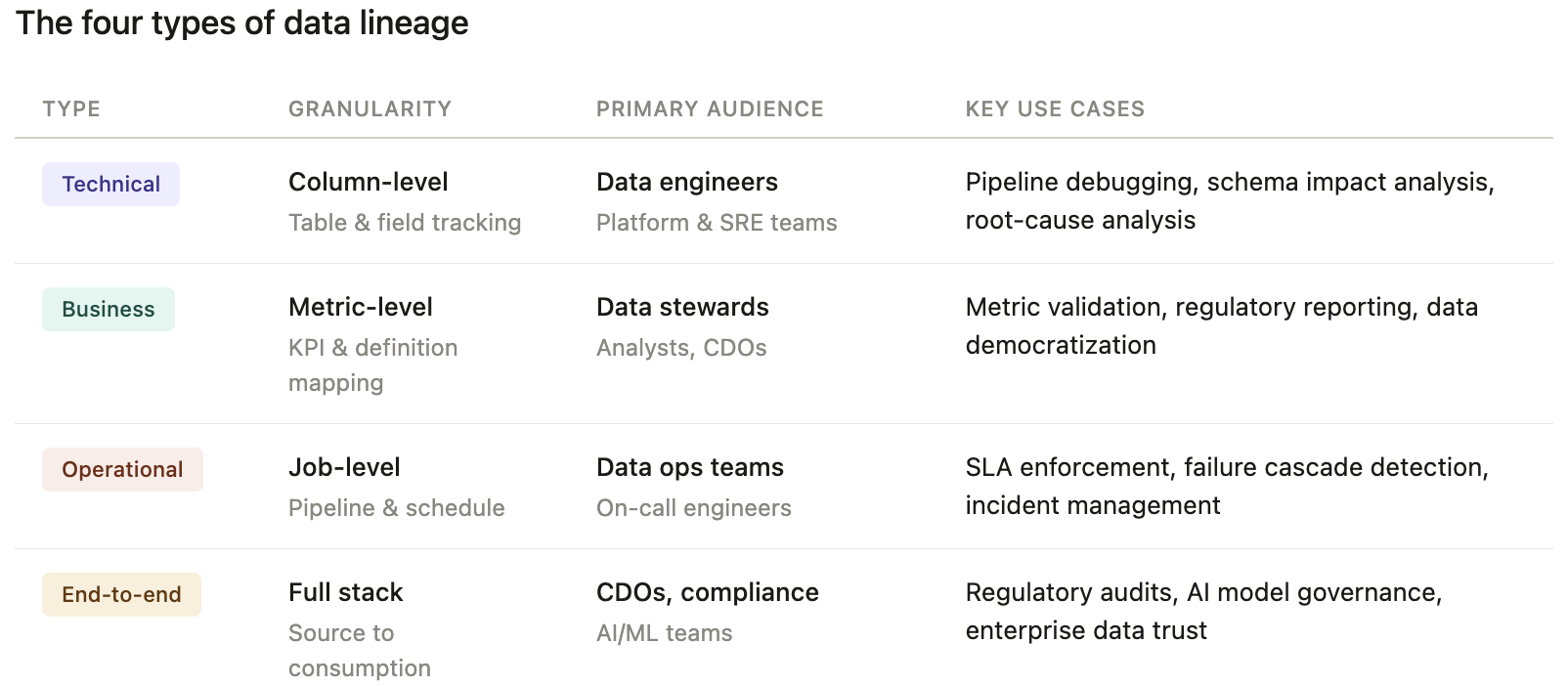
Modern data teams work with four distinct lineage types, each serving a different audience and use case. Understanding which type you need, and when, prevents over-engineering and under-delivering.
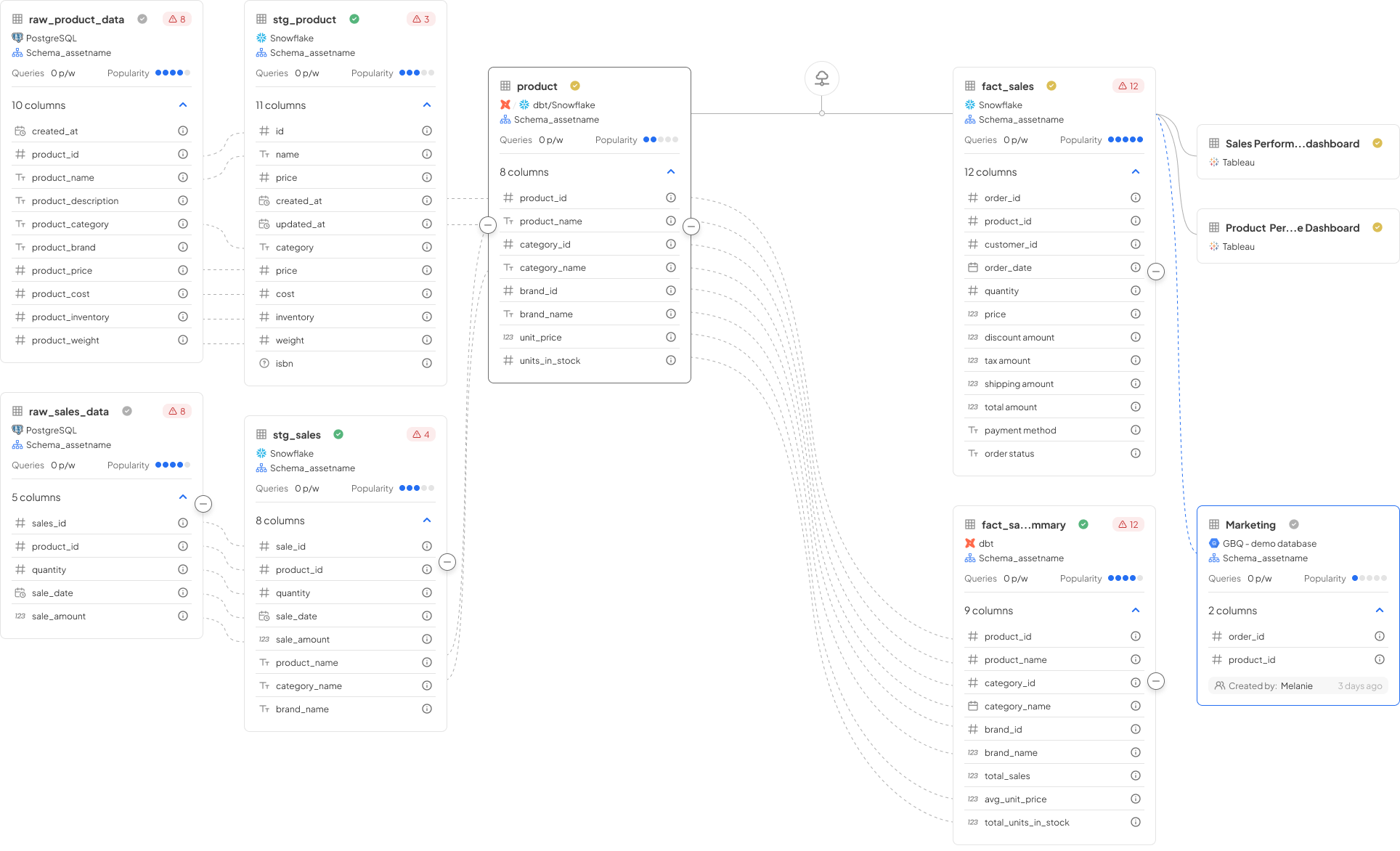
Tracks data movement at the table and column level across systems: databases, ETL pipelines, dbt models, Snowflake, Databricks, and Spark jobs. This is what data engineers live in. It answers "what job touched this table and what did it do to column X?"
Who uses it: Data engineers, platform teams, SREs
Primary use cases: Debugging, impact analysis before schema changes, pipeline root-cause analysis
Connects data assets to business definitions, metrics, and KPIs. It translates "CUST_REV_ADJ_V3" into "Adjusted Customer Revenue as defined by Finance in Q1 2025." Business lineage lives at the intersection of your data catalog, business glossary, and technical lineage.
Who uses it: Data stewards, business analysts, CDOs
Primary use cases: Regulatory reporting, metric validation, data democratization
Shows how pipelines and jobs process data: scheduling, dependencies, SLA tracking, and failure cascades. It answers "which upstream job failing caused this dashboard to go stale?"
Who uses it: Data engineers, data ops teams
Primary use cases: Incident management, SLA enforcement, pipeline observability
Combines all three types above across systems, from raw source data ingested from a CRM or transactional database, through transformation layers, all the way to a BI dashboard or an AI model's feature store. This is the gold standard for governance and AI readiness.
Who uses it: CDOs, compliance officers, AI/ML teams
Primary use cases: Regulatory audits, AI model explainability, enterprise data governance
Decube's Column-Level Lineage maps all four types in a single unified canvas — from source tables through dbt transformations to Tableau dashboards and AI feature pipelines. See how it works →
By 2026, most enterprises have realized that AI success depends far more on data engineering discipline than on model selection. When AI systems generate insights or make decisions, lineage shows exactly which data contributed to those outputs and how it was transformed.
Without lineage, AI models are fed stale, incorrect, or misclassified data — leading to predictions that are wrong and untrustworthy. Gartner's 2025 research identifies lineage as essential for AI trust and accountability, noting that organizations using active metadata analytics can deliver new data assets up to 70% faster.
Decube's TrustyAI is built on this foundation: it uses column-level lineage as the context layer that allows AI agents to reason about data safely, explain outputs, and know when to escalate rather than act.
The compliance landscape in 2026 makes data lineage legally required for many organizations, not merely best practice:
In APAC financial services, regulators from APRA (Australia), BNM (Malaysia), OJK (Indonesia), and BSP (Philippines) are increasingly requiring data provenance documentation as part of model risk and data governance frameworks.
Consider a bank's credit risk model producing anomalous outputs the week before a regulatory submission. Without lineage: teams spend days manually tracing whether the anomaly came from a source system change, an ETL transformation bug, or a model feature calculation error. With column-level lineage: the root cause is identified in minutes — a schema change upstream silently altered a join key, affecting downstream feature computation.
This is not a hypothetical. Data quality issues cost organizations an average of $12.9 million annually (Gartner). Lineage is the mechanism that cuts that cost by making root-cause analysis tractable.

A complete data lineage framework has five essential components working in concert:
Data Sources — the origin systems: operational databases, APIs, SaaS platforms (Salesforce, SAP), file systems, streaming sources (Kafka). Lineage begins here, capturing schema, ownership, and ingestion time.
Transformations — every operation that modifies data: SQL joins, dbt models, Spark jobs, Python scripts, stored procedures. Column-level lineage tracks transformations at field granularity, not just table level. This is the critical distinction between surface-level lineage and genuinely useful lineage.
Data Pipelines — the orchestration layer: Airflow DAGs, ADF pipelines, Fivetran syncs, Glue jobs. Operational lineage maps these dependencies so you know which pipeline failure cascades to which downstream assets.
Destinations — where data lands: data warehouses (Snowflake, BigQuery, Redshift), BI tools (Tableau, Power BI, Looker), AI feature stores, downstream APIs, and reports.
Metadata — the connective tissue: data types, owners, freshness, quality scores, business definitions, and policy tags. Metadata transforms a lineage graph from a technical map into a decision-grade context layer.

Catalog every data source that matters to your organization. This includes the obvious (your primary data warehouse) and the less obvious (spreadsheets that feed financial models, SaaS exports that power marketing analytics, operational databases that feed your AI training pipelines).
Modern lineage platforms automate discovery through connectors — Decube supports 100+ integrations including Snowflake, Databricks, dbt, BigQuery, Tableau, and AWS Glue — but discovery still requires human judgment about what's business-critical versus peripheral.
Document the relationships and dependencies between sources, transformations, and destinations. At the table level, this gives you a high-level flow map. At the column level, it gives you the granular traceability that compliance and AI use cases require.
Column-level lineage is harder to build but exponentially more valuable. When a metric is wrong, column-level lineage tells you exactly which upstream field was miscomputed. Table-level lineage tells you which tables were involved — much less actionable.
Attach business context to the technical lineage graph. This means linking data assets to your business glossary, assigning data owners, tagging PII and sensitive fields, annotating transformation logic in plain language (AI can help translate complex SQL into readable descriptions), and recording SLA expectations.
This stage turns lineage from an engineering artifact into a governance asset that business stakeholders can use.
Lineage that isn't maintained becomes misleading — sometimes worse than no lineage at all. Validation involves automated checks that lineage remains accurate as pipelines evolve, alerting when upstream schema changes could break downstream lineage, and regular audits tying documented lineage to actual observed data flows.
This is where data observability and lineage intersect: observability detects anomalies, lineage tells you where they originated and what they affect.
A data engineer wants to rename a column in a source table. Without lineage: they either ask everyone in Slack (unreliable) or push the change and wait for breakage reports. With column-level lineage: they open the lineage graph, see that 14 downstream tables, 3 dbt models, and 2 Tableau dashboards depend on that column, and plan accordingly — or automate the change propagation entirely.
A revenue dashboard shows a 23% spike that doesn't match operational data. With end-to-end lineage, the data team traces the spike back through the BI layer → the aggregation model → the transformation job → and finds that a currency conversion rate lookup table was updated with incorrect data two days prior. Time to resolution: 8 minutes instead of 8 hours.
For a financial institution under DORA, regulators require evidence that reported figures can be traced to source systems. Lineage provides the auditable chain: this regulatory metric → this aggregation view → these source transactions → this operational database → ingested at this timestamp with this quality score. Without lineage, that evidence is manual, slow, and error-prone.
An ML team's fraud detection model begins drifting. With lineage, they can identify which features changed and trace those features back to upstream data sources — discovering that a third-party data provider changed their API response format, silently altering a key feature. Lineage makes AI systems explainable and their failures diagnosable.
Most early-generation lineage tools operated at the table level. You could see that Table A fed Table B through Process C. Useful, but insufficient for the questions modern data teams actually need to answer.
Column-level lineage tracks data at field granularity. It answers:
The jump from table-level to column-level lineage is the difference between knowing a fire started in a building and knowing which room it started in. Both matter; only one is actionable at the speed modern data teams operate.
Data lineage and data observability are complementary, not competing. Observability tells you that something is wrong. Lineage tells you where it originated and what it affects.
The five pillars of data observability — Freshness, Volume, Schema, Quality, and Lineage — treat lineage as a native dimension of data health, not a separate concern. When a freshness alert fires on a critical reporting table, lineage immediately surfaces which upstream pipeline or source is responsible. When a schema change is detected, lineage shows which downstream consumers will be broken.
This integration is why standalone lineage tools are being consolidated into unified platforms. Decube's Data Observability and Column-Level Lineage modules share a single metadata graph — so lineage context is instantly available when an observability alert fires, and observability health signals are visible within the lineage view.
A data catalog without lineage is a library of books with no record of where they came from or how they relate to each other. Lineage enriches every catalog asset with provenance and dependency context.
The integration works both ways:
This is why Decube's Metadata Management and Data Governance modules are designed to share a single lineage backbone. Context that lives in the catalog is immediately available in the lineage view, and vice versa.
1. Start with column-level, not table-level. Table-level lineage is the floor, not the ceiling. If your tooling only supports table-level lineage, you're operating with significantly reduced utility for debugging, compliance, and AI use cases.
2. Automate capture, don't rely on manual documentation. Manually documented lineage is always stale. Modern platforms extract lineage directly from SQL, dbt models, pipeline metadata, and query logs — ensuring it stays accurate as the stack evolves.
3. Integrate lineage with observability. Lineage without observability tells you the map but not the weather. Observability without lineage tells you there's a storm but not where it started. The combination is significantly more powerful than either alone.
4. Make lineage accessible to business users, not just engineers. Business lineage — connecting technical data flows to business metrics and definitions — is what allows data stewards and analysts to self-serve on governance questions. A lineage graph that only data engineers can read has limited organizational impact.
5. Tie lineage to AI workflows explicitly. Every AI and ML use case in your organization should have its input data mapped through lineage. Training datasets, feature engineering steps, and model serving pipelines all need traceability. This isn't just good practice — it will be legally required for high-risk AI under the EU AI Act.
6. Treat lineage as a living asset. Establish ownership for lineage accuracy. When pipelines change, lineage should update automatically; when it can't, there should be a process for manual review. Stale lineage is misleading lineage.
As the market matures, the features that separate good lineage tools from great ones have become clearer:
Automated extraction — lineage should be captured from SQL, dbt, Spark, and pipeline metadata without manual mapping. If setup requires engineers to document lineage by hand, adoption will fail.
Column-level granularity — as discussed, this is non-negotiable for debugging, compliance, and AI use cases.
Cross-system coverage — your data stack spans multiple tools: ingestion, transformation, orchestration, warehousing, BI. Lineage needs to traverse all of them in a single connected graph, not as siloed views per tool.
Business context integration — lineage nodes should link to business glossary terms, data owners, quality scores, and policy tags. Technical lineage alone serves engineers; contextual lineage serves the whole organization.
Impact analysis — the ability to ask "if I change X, what breaks?" before making a change. This is the feature that saves teams from hours of post-incident debugging.
Integration with observability — lineage and observability should share metadata so that when an alert fires, the lineage context is immediately available.
AI governance support — lineage should extend to ML pipelines, feature stores, and model registries, not just traditional data infrastructure.
Data lineage is the foundation on which data governance, data quality, and AI readiness are built. Without knowing where data comes from, how it transforms, and what depends on it, every other data initiative — compliance reporting, analytics, AI deployment — rests on uncertain ground.
In 2026, the stakes are higher than ever. Regulatory requirements are expanding. AI deployment is accelerating. And the cost of data quality failures is increasingly visible at the business level. Column-level lineage, integrated with observability and catalog capabilities, is what converts raw data infrastructure into a trusted, auditable, AI-ready context layer.
The organizations getting this right aren't treating lineage as a compliance checkbox. They're treating it as the connective tissue that makes everything else work.
Ready to see column-level lineage in action across your data stack? Request a demo or explore the Lineage Canvas.

First step to AI Readiness
Table of Contents
Sneak peek from the data world.











_For%20light%20backgrounds.svg)


.jpg)

