Enroll to explore sandbox
Kindly fill up the following to try out our sandbox experience. We will get back to you at the earliest.
Kindly fill up the following to try out our sandbox experience. We will get back to you at the earliest.
The Data Context Manager is the missing role in enterprise data teams. Learn how this function bridges data governance, domain expertise, and decision intelligence.
Updated on

A Data Context Manager is a domain-embedded role responsible for transforming raw data assets into governed, business-ready intelligence that data teams and decision-makers can trust and act on. The role sits at the intersection of data governance, domain expertise, and decision intelligence.
Most enterprise data teams are drowning in data but starving for context.
A financial analyst runs a report, gets a number, and has no idea if it applies to gross revenue or net. A data engineer builds a pipeline but cannot tell whether the customer_id field refers to a contract holder or an individual account. A CDO tries to govern data quality but finds no one accountable for what "quality" means in the claims processing domain.
This is the context gap. And it is getting worse.
The rise of AI makes context existential, not operational. When AI agents query your data warehouse, they have no intuition. They cannot infer that revenue in the Indonesia entity is booked on a different accrual schedule than revenue in the Singapore entity. They will not ask clarifying questions. They will produce an answer — a confident, well-formatted, deeply wrong answer.
Every organization that has deployed a large language model on top of enterprise data has encountered the same wall: the model is capable, but the data context it operates on is incoherent. The problem is not the model. The problem is that no one owns the context.
The Data Context Manager fixes that.
The Data Context Manager is not a data steward who governs for governance's sake. And they are not a data analyst who builds dashboards. They occupy a distinct role that most org charts do not yet have a name for — which is exactly why the role is so badly needed.
Here is what the job looks like in practice across the data function.
Every function in an enterprise generates its own vocabulary: "churn" in the customer success team means something different from "churn" in the finance team. A Data Context Manager defines, documents, and governs these definitions in a shared business glossary (link: business glossary), ensuring that every metric, dimension, and entity has exactly one authoritative definition in the enterprise data catalog.
Without this, every downstream consumer — analysts, AI agents, BI dashboards — invents their own interpretation. The Data Context Manager ends the ambiguity.
Data lineage (link: data lineage) tells you where a number came from and what touched it on the way. The Data Context Manager curates lineage for the data products their domain depends on: the revenue waterfall report, the regulatory capital model, the customer 360 view. When a number looks wrong, lineage tells you in minutes rather than days.
In regulatory environments governed by BCBS 239 or OJK requirements, lineage is not optional — it is audit evidence. The Data Context Manager makes lineage a living, maintained artifact rather than a project deliverable that goes stale six months after launch.
Data quality rules written by engineers often reflect what is technically possible, not what is business-critical. A Data Context Manager writes quality rules that reflect what the business actually needs: "Loan disbursement amounts must be populated for all records with status = 'approved'" is a business rule, not a technical validation.
They translate these rules into the monitoring layer (Decube, Monte Carlo, Great Expectations) and own the thresholds. When an alert fires, they triage whether it is a pipeline issue or a business reality.
This is the role's most powerful — and most underappreciated — function. As AI agents and natural language query tools proliferate across the enterprise stack, they need a context layer to operate reliably. That context layer is not a technology. It is the accumulated, governed, documented knowledge of what the data means, how it was collected, and under what conditions it can be trusted.
The Data Context Manager builds and maintains that layer. They are, in effect, the human source of truth that teaches AI systems how to reason about domain data without hallucinating.
Data Governance is not a supporting activity for the Data Context Manager. It is the operating framework that gives the role authority, accountability, and measurability.
Without governance, a Data Context Manager is just someone with strong opinions about metadata. With governance, they are the domain authority in a structured accountability model — with policies to enforce, standards to uphold, and metrics to prove their impact.
Data Governance frameworks (link: data governance framework) define who owns data, who can approve changes, and what standards data must meet before it flows downstream. The Data Context Manager sits inside that framework as the domain data owner — not the IT data steward, not the data engineer, but the person accountable for whether business stakeholders can trust and use data in their domain.
In a DAMA-aligned governance model, the Data Context Manager maps directly to the "Data Owner" archetype at the domain level, with escalation paths to the enterprise governance council and direct accountability to the CDO.
Context without policy is just documentation. A Data Context Manager who defines "active customer" in the business glossary has done useful work. A Data Context Manager who embeds that definition into a governed data product, a certification workflow, and an approval-gated lineage model has built an enterprise asset.
Platforms like Decube enable this by connecting the business glossary to data quality monitors, lineage graphs, and certification workflows — turning the Data Context Manager's knowledge into enforceable policy across the data stack.
For enterprises operating in regulated industries — financial services in APAC, healthcare in the US, energy in Europe — data context is a compliance requirement. BCBS 239 mandates that banks demonstrate data lineage and data quality for risk reporting. OJK in Indonesia and MAS in Singapore require data governance frameworks with clear accountability. APRA in Australia expects documented data provenance.
The Data Context Manager is the person who makes compliance concrete. They are not the compliance officer — but they are the domain expert who can produce the lineage evidence, quality certifications, and definitional documentation that compliance requires.
The Data Steward role has existed for decades. The Data Context Manager is a natural evolution of it — shaped by the demands of AI-driven enterprise data functions.
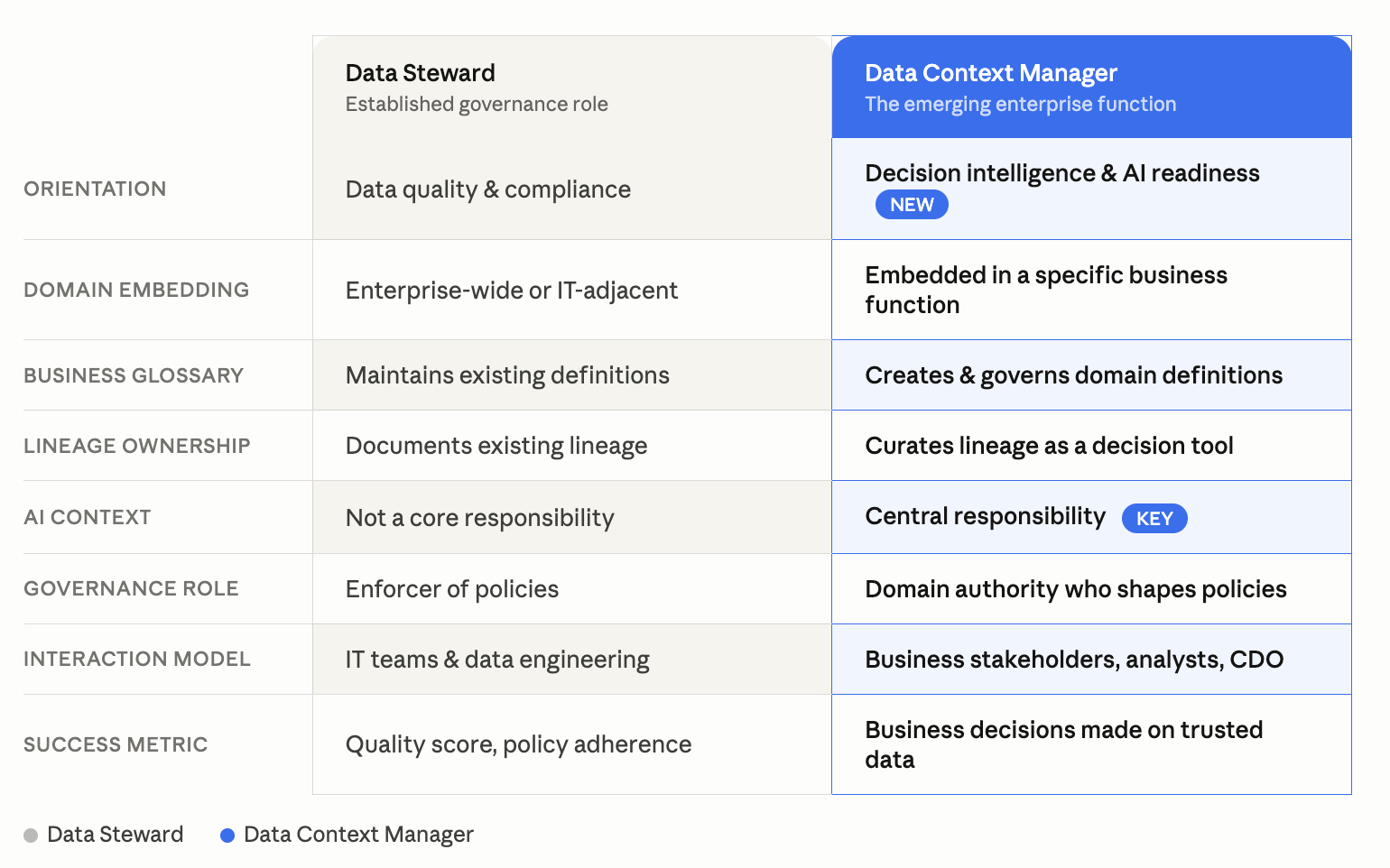
The Data Steward governs data so it meets standards. The Data Context Manager governs context so data produces decisions. Both roles are necessary. The second one is new.
Building a Data Context function is not a technology project. It is an organizational design decision with technology enablement.
Start with the three to five data domains where bad context causes the most damage: revenue reporting, risk modeling, customer analytics, regulatory submissions, supply chain. These are the domains where a single ambiguous metric costs millions, delays decisions, or triggers regulatory findings.
Assign a Data Context Manager to each domain before you buy any technology.
The Data Context Manager must report into — or have a direct relationship with — the enterprise data governance function and the CDO. If the role reports only to IT, it loses domain credibility. If it reports only to the business function, it loses governance authority. The role lives at the intersection.
Define the Data Context Manager's mandate explicitly: they are the domain data owner, with authority to approve business glossary definitions, certify data products, and reject downstream use of data that fails quality standards.
The Data Context Manager's work is only scalable if it lives in a platform that the rest of the organization can access. That platform needs four components: a business glossary (link: business glossary), a data catalog (link: data catalog), a lineage graph (link: data lineage), and a data quality monitoring layer.
Platforms like Decube unify these four components into a single context layer — enabling the Data Context Manager to govern definitions, certify lineage, and monitor quality without stitching together four separate tools.
Most enterprises measure data quality — completeness, accuracy, freshness, uniqueness. The Data Context Manager introduces a new measurement dimension: context quality.
Context quality asks: Is every critical data asset documented? Does every key metric have an approved definition in the business glossary? Is lineage complete for all regulatory reporting pipelines? Are data quality rules defined in business language, not just technical logic?
Define context quality scores for each domain and report them to the CDO alongside traditional data quality metrics.
This is the step most organizations skip — and the one that will matter most in the next 18 months. As enterprises deploy AI agents on top of their data stacks (link: AI agents in data governance), those agents need governed context to function reliably.
The Data Context Manager defines what context AI agents can consume from their domain: which metrics are certified for AI use, which definitions are authoritative, which quality thresholds an asset must meet before an AI agent can query it. This is not a technical configuration — it is a governance decision. The Data Context Manager makes it.
The return on a Data Context Manager is measurable — but most organizations measure it in the wrong place.
The direct costs of contextless data are: analyst retime spent resolving metric definitions, data incidents caused by ambiguous quality standards, regulatory findings from incomplete lineage, and AI model errors from ungoverned context.
Incident reduction: Enterprises with mature data governance — including documented context and defined ownership — report significantly fewer high-severity data incidents. The Decube incident detection value driver alone shows that catching a single P1 data incident before it reaches a board report can save hundreds of thousands of dollars in remediation costs.
Regulatory efficiency: For banks under BCBS 239 or insurers under APRA CPS 220, a dedicated Data Context Manager reduces audit preparation time by enabling on-demand lineage evidence and quality certification. A single regulatory submission cycle can consume weeks of manual data tracing without this role.
AI agent reliability: An AI agent operating with governed context produces dramatically fewer hallucinations on domain-specific queries.
The Data Context Manager does not show up as a cost center on a P&L. They show up as the reason your AI investment didn't fail, your regulatory audit went smoothly, and your CDO could actually trust the number on slide three of the board presentation.
What is a Data Context Manager?
A Data Context Manager is a domain-embedded role responsible for curating, governing, and communicating the business context that makes data trustworthy and decision-ready. They own business glossary definitions, data lineage for critical assets, and domain-level data quality standards. The role sits at the intersection of data governance and domain expertise, reporting into or alongside the enterprise CDO function.
How is a Data Context Manager different from a Data Steward?A Data Steward enforces data quality and governance policies — primarily ensuring data meets defined standards. A Data Context Manager does this and extends it further: they are responsible for making data decision-ready and AI-ready. The Data Context Manager creates the governed context layer that AI agents, analysts, and business stakeholders depend on to trust and use data correctly. The Data Steward role is IT-adjacent; the Data Context Manager role is business-embedded.
What skills does a Data Context Manager need?
The role requires a combination of domain expertise, data literacy, and governance knowledge. A strong Data Context Manager understands the business function's data landscape deeply (what the metrics mean, how they are collected, what can go wrong), can translate that knowledge into governed metadata, and can navigate enterprise data governance structures. SQL literacy is useful; deep engineering skills are not required. What matters most is the ability to bridge business language and data infrastructure.
Does every enterprise function need a Data Context Manager?
Not immediately. Organizations should prioritize the role in domains where data drives high-stakes decisions or regulatory obligations: finance, risk, customer analytics, supply chain, and compliance. As AI agents expand across the enterprise, every function that produces or consumes governed data assets will eventually need this capability — either as a dedicated role or embedded in a domain data lead.
How does Data Governance enable the Data Context Manager role?
Data Governance provides the framework — the policies, accountabilities, and standards — that gives the Data Context Manager authority. Without governance, context work is informal and ungoverned, making it difficult to enforce or scale. With a governance framework (DAMA-aligned or equivalent), the Data Context Manager operates as the domain data owner with a clear mandate, escalation path, and accountability structure. Governance is what turns context management from a good idea into an enterprise function.
How does the Data Context Manager support AI initiatives?
AI agents and natural language query tools require accurate, governed context to produce reliable outputs. Without it, they hallucinate metric definitions, misinterpret relationships between data entities, and produce confident but wrong answers. The Data Context Manager builds and maintains the governed context layer — certified definitions, curated lineage, documented quality standards — that AI agents consume. This is not a technical handoff; it is an ongoing governance responsibility that sits permanently with the Data Context Manager.

First step to AI Readiness
Table of Contents
Sneak peek from the data world.











_For%20light%20backgrounds.svg)



.jpg)
